Weekly Adventures: Doom Reinforcement Learning

Ah yes, I wanted to get back into Machine Learning. Using Machine Learning to identify handwritten digits, Image Recognition and more seems boring through. I want something more exciting, more fun, and what better way to get started than through making my very own Game AI?
Why PyTorch
There are many Machine Learning courses online. I tried following some guides and testing much of the code locally and on Google Colab.
The problem is they don’t work half the time. I see things like this:
tf.reset_default_graph()
AttributeError: module 'tensorflow' has no attribute 'reset_default_graph'
Because Tensorflow 2 exists, backwards compatibility with old libraries is broken and stuff doesn’t work as well. Also installing old TensorFlow is a pain. I’m thinking I need to code this from scratch and stuff but Tensorflow is also generally not as easy to read for me. I don’t understand half the function names like what is this supposed to mean?
gradient_function = K.gradients(cost_function, model_input_layer)[0]
grab_cost_and_gradients_from_model = K.function([model_input_layer], [cost_function, gradient_function])
I realised that PyTorch exists. Just a simple google search of a PyTorch Tutorial gets me this official guide on the first entry. This guide is a wonderful entry into using the library. PyTorch offers some benefits like
- Being more Pythonic and object-oriented apparently. Basically, the code is easier to read.
- The recipes on the official guide work almost all the time (meanwhile, the ones I find with Tensorflow work like 10% of the time)
- One of the biggest features that distinguish PyTorch from TensorFlow is declarative data parallelism: you can use torch.nn.DataParallel to wrap any module and it will be (almost magically) parallelized over batch dimension. This way you can leverage multiple GPUs with almost no effort.
Concept
Reinforcement Learning
Very Brief and Oversimplified Explanation (I may come back and improve this if I feel like it):
There is an environment (like a game).
You are given it’s current state (image, score, whatever)
- The Agent(Program) can take certain actions
- For a certain action and state, it will receive a reward (either positive or negative score)
2. The agent wants to maximise the reward. It uses a Deep Neural Network to predict the action which will give the best value. The Agent then takes that action (Value-Based Method)
3. Using the rewards it recieves in real time, the Agent trains itself to be better at predicting and interacting in the environment.
Some other concepts
Exploration/ Exploitation Trade off
What is the probability the agent should exploit: Take the most optimal action vs
- explore: Doing other actions to potentially discover even more optimal actions
2. The reward decreases over time for the same action
3. Time
- In some games, time is an important consideration (eg. is an enemy moving towards you).
- One way to solve this is by stacking frames (putting a few frames together and passing it into the machine learning model)
4. Memory
- The agent stores past experiences, and randomly picks some of them for training to avoid making the same mistakes again
Useful resources to learn more
What I Did
Combine this and this to make my own Doom playing AI that works. Since I actually can’t find a simple one that works.
What it basically does
- Stack the frames
- Runs it through a DDQN network (I’m not qualified to write about this yet)
- ???
- Profit
Training
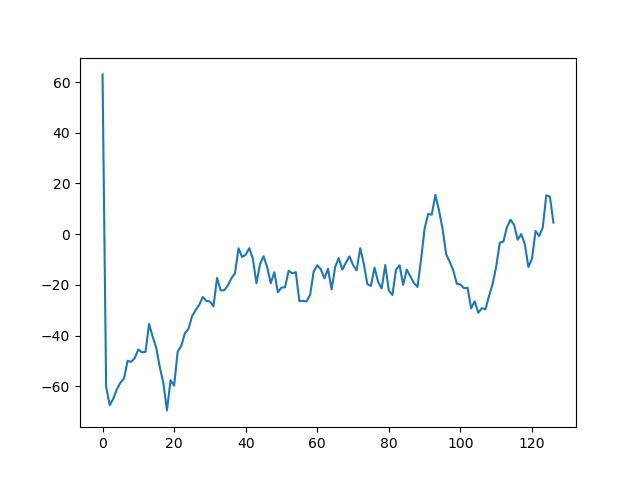
Err… wel… machine learning is a long process.
Some estimates (on my 2017 Core i5 Laptop, AMD Radeon Graphics(Entry Level) )
- The reward score will fluctuate, but to see improvement, you have to wait for about 30 min to see significant improvement
- About 45min to see single digit negative reward?
- About 1h 10min to see positive rewards? 2h to see consistent positive rewards?
- The memory alone is like 2.3GB? Prepare your RAM for this
- 2.5h for double digit positive rewards?
DQN was a shock though. It trained to have double-digit 70–80s rewards in like 45 min. Check my repo for more info
TLDR
- Tensorflow 2 is something that exists. Try PyTorch for less compatibility issues
- Bla Bla Deep Q Learning stuff
- I made a DDQN Doom AI that works ok enough I guess
Originally published at https://hackin7.github.io.


